Sparkの全体像
Executorとかパーティションの概念のような前提となるようなSparkの構成要素
Sparkのメモリ管理の全体像
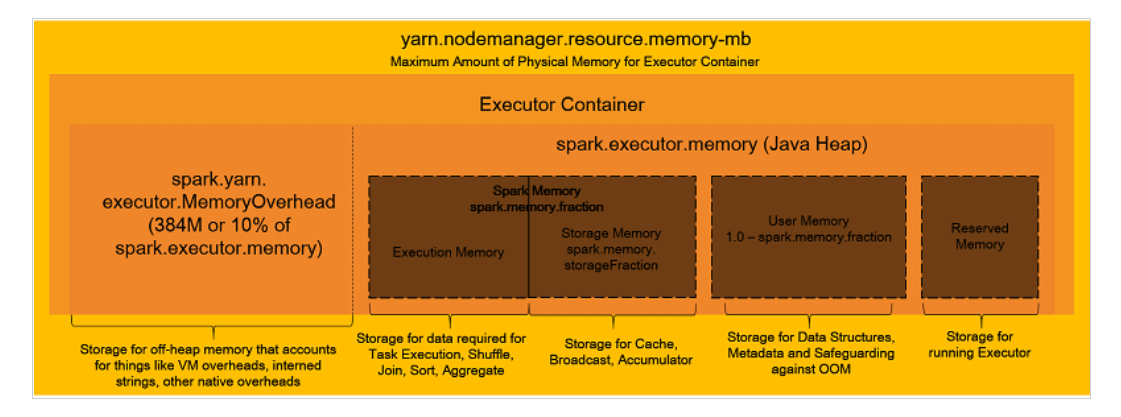
メモリ管理のパラメータ
上記ブログに記載があるspark.dynamicAllocation.enabledをFalseにした場合の各インスタンスタイプとノード数に合わせた各パラメータの計算。計算式についてはこのExcel
に埋め込んである。黄色セル部分を各インスタンスタイプや実際の環境に合わせて変えれば自動計算してくれるはず。
あくまで初期サイジングとして実施すべきであって適宜チューニングの余地がありm特にパーティション数については実際に動かして決めるべき。
| インスタンスタイプ | r5.12xlarge | m5.8xlarge |
|---|---|---|
| vCPU | 48 | 32 |
| メモリ | 384 | 128 |
| ノード数 | 5 | 5 |
| spark.executor.cores:エグゼキュータあたりの仮想コアの数 | 5 | 5 |
| spark.executor.memory:Executorが使用するメモリのサイズ | 9g | 6g |
| spark.yarn.executor.memoryOverhead:Executorが使用するメモリ分のオーバーヘッドのサイズ | 1g | 1g |
| spark.driver.memory:Driverのために使用するメモリのサイズ | 9g | 6g |
| spark.driver.cores:Driverのために使用する仮想コアの数 | 5 | 5 |
| spark.executor.instances :インスタンスあたりのExecutorの数 | 44 | 29 |
| spark.default.parallelism:Partition数のデフォルト値 | 440 | 290 |
その他のパラメータ
その他パラメータについてはブログ側に記載されているパラメータと、Spark側のマニュアルと見比べつつ、必要なものついて設定すれば良いと思う。
[
{
"Classification": "yarn-site",
"Properties": {
"yarn.nodemanager.vmem-check-enabled": "false",
"yarn.nodemanager.pmem-check-enabled": "false"
}
},
{
"Classification": "spark",
"Properties": {
"maximizeResourceAllocation": "false"
}
},
{
"Classification": "spark-defaults",
"Properties": {
"spark.driver.memory": "39G",
"spark.driver.cores": "5",
"spark.executor.memory": "39G",
"spark.executor.cores": "5",
"spark.executor.instances": "14",
"spark.executor.memoryOverhead": "5G",
"spark.driver.memoryOverhead": "5G",
"spark.default.parallelism": "140",
"spark.sql.shuffle.partitions": "140",
"spark.network.timeout": "800s",
"spark.executor.heartbeatInterval": "60s",
"spark.dynamicAllocation.enabled": "false",
"spark.memory.fraction": "0.80",
"spark.memory.storageFraction": "0.30",
"spark.executor.extraJavaOptions": "-XX:+UseG1GC -XX:+UnlockDiagnosticVMOptions -XX:+G1SummarizeConcMark -XX:InitiatingHeapOccupancyPercent=35 -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:OnOutOfMemoryError='kill -9 %p'",
"spark.driver.extraJavaOptions": "-XX:+UseG1GC -XX:+UnlockDiagnosticVMOptions -XX:+G1SummarizeConcMark -XX:InitiatingHeapOccupancyPercent=35 -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:OnOutOfMemoryError='kill -9 %p'",
"spark.yarn.scheduler.reporterThread.maxFailures": "5",
"spark.storage.level": "MEMORY_AND_DISK_SER",
"spark.rdd.compress": "true",
"spark.shuffle.compress": "true",
"spark.shuffle.spill.compress": "true",
"spark.serializer": "org.apache.spark.serializer.KryoSerializer"
}
}
]
参考資料
Apache Hadoop 3.3.1 – Using Memory Control in YARN