はじめに
DuckDB がなぜ速いのか。pip install するだけで使えるのに、なぜ大規模データの集計を高速に処理できるのか。本記事ではその内部構造を解説する。
DuckDB の設計は 2020年の論文 Data Management for Data Science — Towards Embedded Analytics (CIDR 2020)に基づいている。速さの核心は以下の3点にある。
- 列指向ストレージ — 必要な列だけ読む
- ベクトル化実行 — 2048行単位のバッチ処理
- クエリオプティマイザ — 不要な処理を事前に除去
列指向ストレージとは
行指向と列指向の違い
一般的なデータベース(MySQL, PostgreSQL 等)は行指向ストレージを採用している。1行のデータが連続してディスクに並ぶ。
行指向(Row Store)
┌──────────────────────────────────────┐
│ id=1, name="Alice", score=95.5, ... │ ← 1行目
│ id=2, name="Bob", score=87.0, ... │ ← 2行目
│ id=3, name="Charlie",score=92.3, ... │ ← 3行目
└──────────────────────────────────────┘
DuckDB は列指向ストレージを採用している。同じ列のデータが連続して並ぶ。
列指向(Column Store)
┌────────────────────────┐
│ id: 1, 2, 3, ... │ ← id 列
│ name: Alice, Bob, ... │ ← name 列
│ score: 95.5, 87.0, ... │ ← score 列
└────────────────────────┘
なぜ分析クエリが速くなるか
SELECT AVG(score) FROM users という集計クエリを考える。
- 行指向: 全行を読んで
scoreだけ取り出す必要がある。idやnameも無駄に読む - 列指向:
score列だけを連続して読める。I/O が最小化される
さらに、同じ型のデータが連続するため、圧縮効率が大幅に向上する。
ベクトル化実行
1行ずつ vs バッチ処理
従来のデータベースは「行ごと処理」(Volcano Model)が主流だった。
従来モデル(Volcano Model)
クエリ実行エンジン
↓ 1行リクエスト
フィルタノード
↓ 1行リクエスト
スキャンノード
→ 1行ずつ返す
DuckDB は「ベクトル化実行」で、一度に 2048 行をまとめて処理する。
ベクトル化実行(Vectorized Execution)
クエリ実行エンジン
↓ 2048行まとめてリクエスト
フィルタノード(2048行をSIMDで一括評価)
↓ 結果の2048行
スキャンノード
→ 2048行を一括で返す
このアプローチの利点は以下の通り。
| 比較軸 | Volcano Model | ベクトル化 |
|---|---|---|
| 関数呼び出し回数 | 行数分 | 行数 / 2048 |
| CPU キャッシュ効率 | 低い | 高い |
| SIMD 命令の活用 | 困難 | 積極活用 |
| CPUパイプライン | 途切れやすい | 連続して動く |
SIMD(Single Instruction, Multiple Data)
現代の CPU は一命令で複数のデータを同時に処理できる(SIMD)。ベクトル化実行はこれを最大限に活用する。
SIMD 演算の例(128ビット SIMD で 4つの int32 を同時加算)
[1, 2, 3, 4]
[5, 6, 7, 8]
↓ SIMD 加算(1命令)
[6, 8, 10, 12]
クエリオプティマイザ
DuckDB は実行前にクエリを最適化し、不要な処理を取り除く。
Predicate Pushdown(述語プッシュダウン)
フィルタ条件をできる限り早い段階で適用する。
SELECT name FROM users WHERE score > 90;
最適化前:
全行スキャン → JOIN/集計 → フィルタ(score > 90) → name を取得
最適化後:
スキャン時にフィルタ(score > 90) → 該当行のみ処理 → name を取得
読み込むデータ量が大幅に減る。
Projection Pushdown(射影プッシュダウン)
クエリで使わない列は最初から読まない。
SELECT name, score FROM users; -- id は不要
id 列はディスクから読み込まれない。列指向ストレージと組み合わさることで効果が高い。
並列クエリ実行
DuckDB はマルチコアを自動的に活用する。デフォルトで論理コア数のスレッドを使ってクエリを並列実行する。
import duckdb
# スレッド数を確認
con = duckdb.connect()
print(con.execute("SELECT current_setting('threads')").fetchone())
# → ('4',)
大きなテーブルのスキャンや集計は自動的に分割され、各コアで並列処理される。
メモリ管理と out-of-core 処理
DuckDB はメモリに収まらない大規模データも処理できる。
- バッファプール: 頻繁にアクセスするデータをメモリにキャッシュ
- out-of-core 処理: メモリ不足時はディスクにスピルして継続実行
- メモリ上限の設定:
SET memory_limit='4GB'で明示的に制限も可能
SET memory_limit = '4GB';
SET threads = 2;
TPC-H ベンチマーク実測
TPC-H は OLAP 性能の業界標準ベンチマーク。DuckDB の tpch 拡張を使えば、データ生成からクエリ実行まで完結する。
import duckdb, time
con = duckdb.connect()
con.execute('INSTALL tpch; LOAD tpch;')
con.execute('CALL dbgen(sf=1);') # sf=N で Scale Factor を指定
Scale Factor(SF)は生成するデータ量の倍率で、SF=1 で約 600 万行の lineitem テーブルが生成される。
計測クエリ
3種類のクエリで実行時間を計測した。
Q1: 全行スキャン + 集計(lineitem の全行を読んでグループ集計)
SELECT l_returnflag, l_linestatus,
COUNT(*) AS count_order, SUM(l_quantity) AS sum_qty
FROM lineitem
WHERE l_shipdate <= DATE '1998-09-02'
GROUP BY l_returnflag, l_linestatus
ORDER BY l_returnflag, l_linestatus;
Q6: フィルタ集計(条件絞り込み後に単一集計)
SELECT SUM(l_extendedprice * l_discount) AS revenue
FROM lineitem
WHERE l_shipdate >= DATE '1994-01-01'
AND l_shipdate < DATE '1995-01-01'
AND l_discount BETWEEN 0.05 AND 0.07
AND l_quantity < 24;
Q5: 6テーブル JOIN + 集計(最も複雑なクエリ)
SELECT n_name, SUM(l_extendedprice * (1 - l_discount)) AS revenue
FROM customer, orders, lineitem, supplier, nation, region
WHERE c_custkey = o_custkey
AND l_orderkey = o_orderkey
AND l_suppkey = s_suppkey
AND c_nationkey = s_nationkey
AND s_nationkey = n_nationkey
AND n_regionkey = r_regionkey
AND r_name = 'ASIA'
AND o_orderdate >= DATE '1994-01-01'
AND o_orderdate < DATE '1995-01-01'
GROUP BY n_name ORDER BY revenue DESC;
実測結果(SF=0.1 〜 SF=20)
各 SF で3回計測した平均値を記録した。
| SF | lineitem 行数 | Q1 (ms) | Q6 (ms) | Q5 (ms) |
|---|---|---|---|---|
| 0.1 | 600,572 | 10.7 | 2.8 | 11.4 |
| 1 | 6,001,215 | 31.0 | 13.3 | 41.5 |
| 5 | 29,999,795 | 121.4 | 58.6 | 194.2 |
| 10 | 59,986,052 | 330.4 | 124.9 | 438.3 |
| 20 | 119,994,608 | 491.6 | 240.4 | 934.3 |
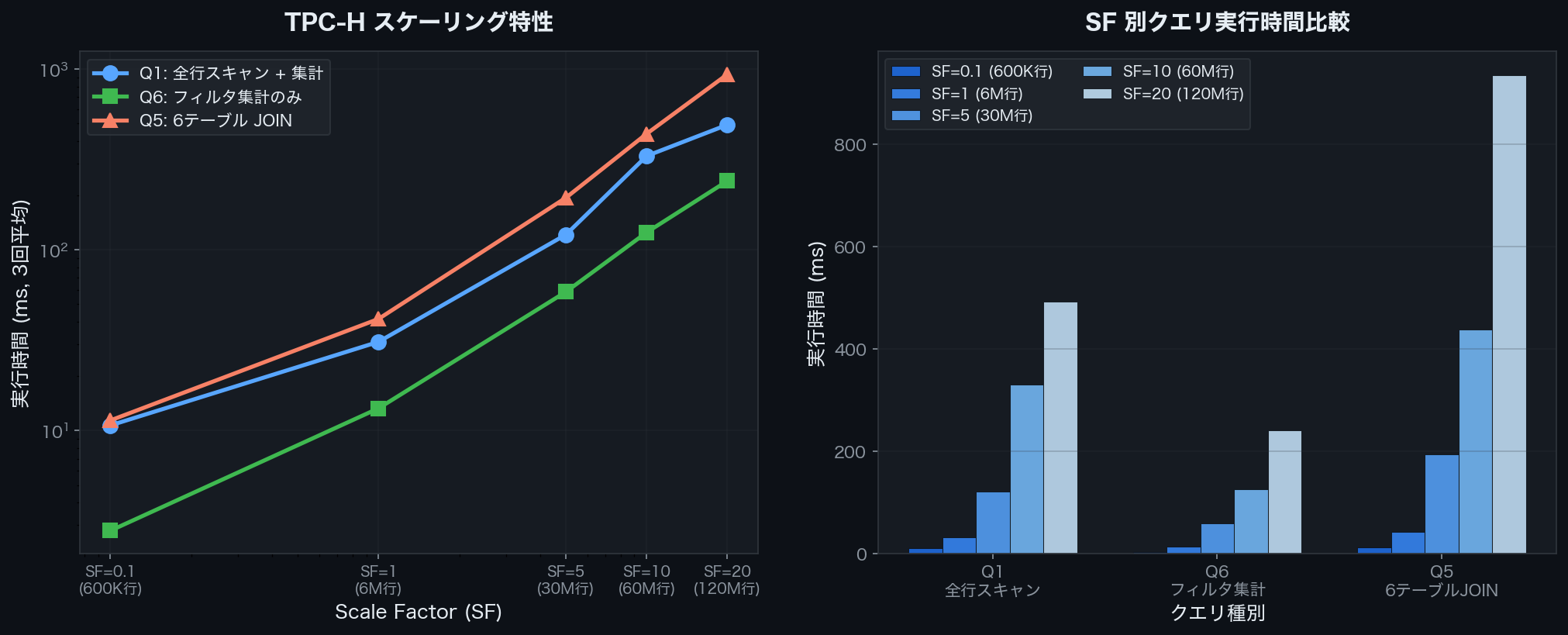 TPC-H SF=0.1〜20 における Q1/Q6/Q5 の実行時間比較(DuckDB v1.4.4)
TPC-H SF=0.1〜20 における Q1/Q6/Q5 の実行時間比較(DuckDB v1.4.4)
SF が10倍になると実行時間はおおよそ10〜20倍に増加する。Q5(6テーブル JOIN)はデータ量増加の影響を最も受けやすく、SF=20 では 934ms まで増加した。一方 Q6(シンプルなフィルタ集計)は 240ms と比較的抑えられている。
列指向ストレージによる I/O 削減と SIMD ベクトル化の効果で、1億2000万行のデータでも Q1 集計が 500ms 以内に収まる。
Apache Arrow との関係
DuckDB は内部的に Apache Arrow の列指向フォーマットを活用している。
- ゼロコピー転送: Pandas や Polars との間でデータコピーなしに転送できる
- 相互運用性: Arrow フォーマットを介して他のツールと高速連携
- メモリ効率: Arrow の効率的なメモリレイアウトをそのまま利用
import duckdb
con = duckdb.connect()
# Arrow Table として取得(ゼロコピー)
arrow_table = con.execute("SELECT * FROM range(1000000) t(i)").fetch_arrow_table()
print(arrow_table.schema)
まとめ
DuckDB の速さは以下の組み合わせによる。
| 技術 | 効果 |
|---|---|
| 列指向ストレージ | 必要な列だけ読む → I/O 最小化 |
| ベクトル化実行 | 2048行バッチ → CPU 効率最大化 |
| Predicate Pushdown | フィルタを早期適用 → 処理行数削減 |
| Projection Pushdown | 不要列を読まない → I/O 削減 |
| 並列実行 | マルチコアを自動活用 |
| Apache Arrow | ゼロコピーでツール間連携 |
60万行の集計が10ms台、1億行超でも数百ms以内に収まる。この性能がサーバー不要・インストール1行で手に入るのが DuckDB の強みとなる。
