I’ve only just gotten used to the term “data lake,” but it seems the next trend has already emerged. Parquet, ORC, and Avro are column-oriented “file formats” commonly used in data lake services, but there are also “table formats” such as Apache Hudi, Delta Lake, and Apache Iceberg. In AWS, the Governed Tables available in Lake Formation correspond to this. Here are some rough notes on that topic.
| Table Format | Developer | Notes |
|---|---|---|
| Apache Hudi | Uber | Donated to Apache |
| Delta Lake | Databricks | |
| Apache Iceberg | Netflix | Donated to Apache |
I’ve only touched Iceberg available in Athena, but in practice it consists of parquet files and metadata files.
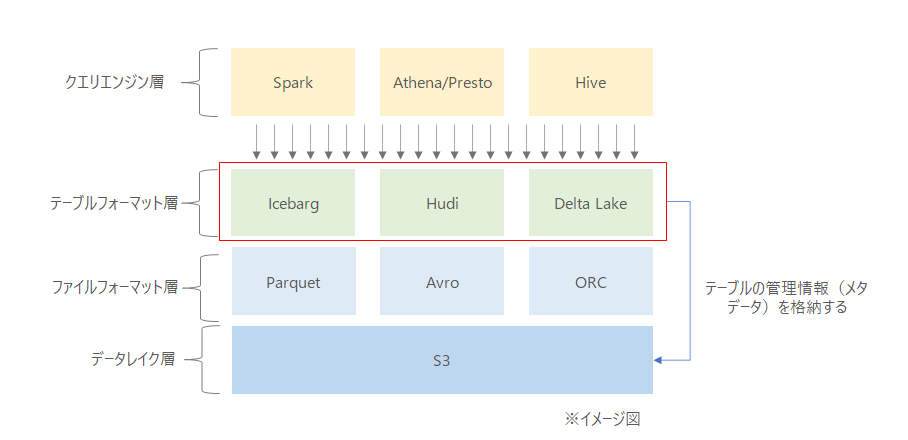
Conceptual Diagram
I understand that the red-bordered area was added. It’s an abstraction layer in the middle describing how the files are structured to form a table. With this addition, ACID updates and deletions and data versioning become possible.
Note: This diagram does not represent something like Iceberg supporting ORC.
For example, when creating an Iceberg table from Athena, the following file format and metadata are generated:
% aws s3 ls s3://xxxxx/iceberg_table/ --recursive
2021-12-06 21:30:30 0 iceberg_table/
2021-12-07 13:42:38 453 iceberg_table/data/3494c159//iceberg_table/category=macbook/id_bucket=4/82f67f06-a0e1-4522-ba48-3cbe6d3a8be6.parquet
2021-12-07 13:45:35 438 iceberg_table/data/4b0be337//iceberg_table/category=macbook/id_bucket=4/dde0a679-84f8-46f4-891e-33355a25f396.parquet
2021-12-07 13:40:55 1417 iceberg_table/metadata/00000-60ff8e64-b2c6-4cc1-89b1-dc740816cf2d.metadata.json
2021-12-07 13:42:39 2336 iceberg_table/metadata/00001-b6262f06-8805-40c6-9b28-7b1d361f3705.metadata.json
2021-12-07 13:45:36 3289 iceberg_table/metadata/00002-79008873-1a1b-44db-830a-cdeae6c87dde.metadata.json
2021-12-07 13:42:38 7033 iceberg_table/metadata/958b8acb-2800-473b-b55e-486333344762-m0.avro
2021-12-07 13:45:35 7033 iceberg_table/metadata/b8518cfe-ffeb-4b58-880b-81ffe1156b85-m0.avro
2021-12-07 13:42:39 4270 iceberg_table/metadata/snap-1296825016097872104-1-958b8acb-2800-473b-b55e-486333344762.avro
2021-12-07 13:45:35 4340 iceberg_table/metadata/snap-6943776344382491461-1-b8518cfe-ffeb-4b58-880b-81ffe1156b85.avro
Benefits
To access data as a table, the schema, data statistics, and more are managed as metadata in addition to just the file path. The following benefits are reported:
- ACID updates and deletions of data lake files
- Time travel (data versioning)
- Easy schema changes
- Performance
The official Iceberg page describes it as follows:
Schema evolution supports add, drop, update, or rename, and has no side-effects
Hidden partitioning prevents user mistakes that cause silently incorrect results or extremely slow queries
Partition layout evolution can update the layout of a table as data volume or query patterns change
Time travel enables reproducible queries that use exactly the same table snapshot, or lets users easily examine changes
Version rollback allows users to quickly correct problems by resetting tables to a good state
Notes
I’d like to watch how this Lakehouse, as an evolution of the Data Lake, develops. AWS has also begun implementing features in this area, so I’ll closely watch how it will be used going forward.
Reference: https://www.integrate.io/jp/blog/meet-the-data-lakehouse-ja/#lakehouse
References
- Amazon Athena Apache IcebergテーブルフォーマットによるACID Transactionを試してみました! | DevelopersIO
- 更新できるデータレイクを作る 〜Apache Hudiを用いたユーザデータ基盤の刷新〜 - Gunosy Tech Blog
- AWS Lake Formation が、Governed Tables、ストレージの最適化、および行レベルのセキュリティをサポート
- AWS Lake Formation による効果的なデータレイクの構築 パート 1: governed tableを作成する | Amazon Web Services ブログ