はじめに
自分のHugoブログ(GitHub Pages)に対して、以下2つのアプローチでAI/LLM向けのインターフェースを実装した。
- MCP Server - Claude Codeから記事の検索・閲覧ができるMCPサーバー(リポジトリのクローン不要、HTTPフェッチ方式)
- llms.txt - Webサイト上でLLM向けにコンテンツを公開する標準フォーマット
MCP(Model Context Protocol)とは
MCPはAnthropicが提唱するプロトコルで、AIモデルが外部のデータソースやツールと連携するための標準的な仕組みである。MCP Serverを作ることで、Claude CodeなどのAIツールからブログの記事検索・閲覧が可能になる。
MCP Serverの実装
データ取得方式
当初はリポジトリをクローンしてローカルのMarkdownファイルを直接読む方式だったが、利用者にクローンを強いるのは不便なため、サイトが公開しているllms-full.txtをHTTPで取得する方式に変更した。
┌──────────────┐ HTTP GET ┌──────────────────────┐
│ MCP Server │ ───────────────── │ zatoima.github.io │
│ (Node.js) │ /llms-full.txt │ (GitHub Pages) │
└──────────────┘ └──────────────────────┘
│
│ stdio
▼
┌──────────────┐
│ Claude Code │
└──────────────┘
これにより、リポジトリのクローンは不要になった。MCP Serverのソースコードだけ取得してビルドすればよい。データは10分間キャッシュされ、キャッシュ期限後は自動で再取得される。
構成
mcp-server/
├── package.json
├── tsconfig.json
├── src/
│ └── index.ts
└── dist/
└── index.js
依存ライブラリは @modelcontextprotocol/sdk のみ。Node.js標準のfetchでllms-full.txtを取得し、テキストパースで記事データを抽出する。
提供ツール
MCP Serverでは5つのツールを実装した。
| ツール名 | 説明 |
|---|---|
search_posts |
キーワードでタイトル・本文・タグを全文検索 |
read_post |
slugまたはタイトルの一部から記事全文を取得 |
list_posts |
記事一覧の取得(タグ・カテゴリ・年でフィルタ可) |
list_tags |
全タグと記事数の一覧 |
blog_stats |
ブログの統計情報(記事数、年別投稿数、人気タグ) |
実装のポイント
llms-full.txtは---で区切られた記事の連続テキストであるため、これをパースして構造化データに変換する。
import { McpServer } from "@modelcontextprotocol/sdk/server/mcp.js";
import { StdioServerTransport } from "@modelcontextprotocol/sdk/server/stdio.js";
import { z } from "zod";
const SITE_URL = "https://zatoima.github.io";
// llms-full.txtからデータを取得・パース
async function getPosts(): Promise<BlogPost[]> {
const res = await fetch(`${SITE_URL}/llms-full.txt`);
const text = await res.text();
return parseLlmsFullTxt(text); // テキストを記事データに変換
}
// ツール登録の例: 記事検索
server.tool(
"search_posts",
"ブログ記事をキーワードで検索する",
{
query: z.string().describe("検索キーワード"),
limit: z.number().optional().default(10),
},
async ({ query, limit }) => {
const posts = await getPosts();
const q = query.toLowerCase();
const results = posts
.filter(
(p) =>
p.title.toLowerCase().includes(q) ||
p.content.toLowerCase().includes(q) ||
p.tags.some((t) => t.toLowerCase().includes(q))
)
.slice(0, limit);
// ... 結果を返す
}
);
セットアップ
リポジトリ全体のクローンは不要。MCP Serverのソースコードだけ取得してビルドする。
# MCP Serverのソースを取得してビルド
git clone --depth 1 --filter=blob:none --sparse https://github.com/zatoima/zatoima.github.io.git
cd zatoima.github.io && git sparse-checkout set mcp-server
cd mcp-server && npm install && npx tsc
# Claude Codeに登録
claude mcp add zatoima-blog node $(pwd)/dist/index.js
登録後、Claude Codeのセッション内で以下のように使用できる。
# 記事検索
mcp__zatoima-blog__search_posts(query="Aurora")
# 統計情報
mcp__zatoima-blog__blog_stats()
llms.txtの実装
llms.txtとは
llms.txtはWebサイトの内容をLLMに理解させるためのフォーマットである。robots.txtのAI版のようなもので、サイトの概要と記事一覧をプレーンテキストで提供する。
/llms.txt- 記事タイトル・URL・タグの一覧(軽量版)/llms-full.txt- 全記事の本文を含む完全版
Hugoでの生成方法
1. hugo.tomlにカスタム出力フォーマットを定義
[mediaTypes]
[mediaTypes."text/llms"]
suffixes = ["txt"]
[mediaTypes."text/llms-full"]
suffixes = ["txt"]
[outputFormats]
[outputFormats.llms]
mediaType = "text/llms"
baseName = "llms"
isPlainText = true
notAlternative = true
[outputFormats.llms-full]
mediaType = "text/llms-full"
baseName = "llms-full"
isPlainText = true
notAlternative = true
[outputs]
home = ["HTML", "RSS", "JSON", "llms", "llms-full"]
2. テンプレートファイルの作成
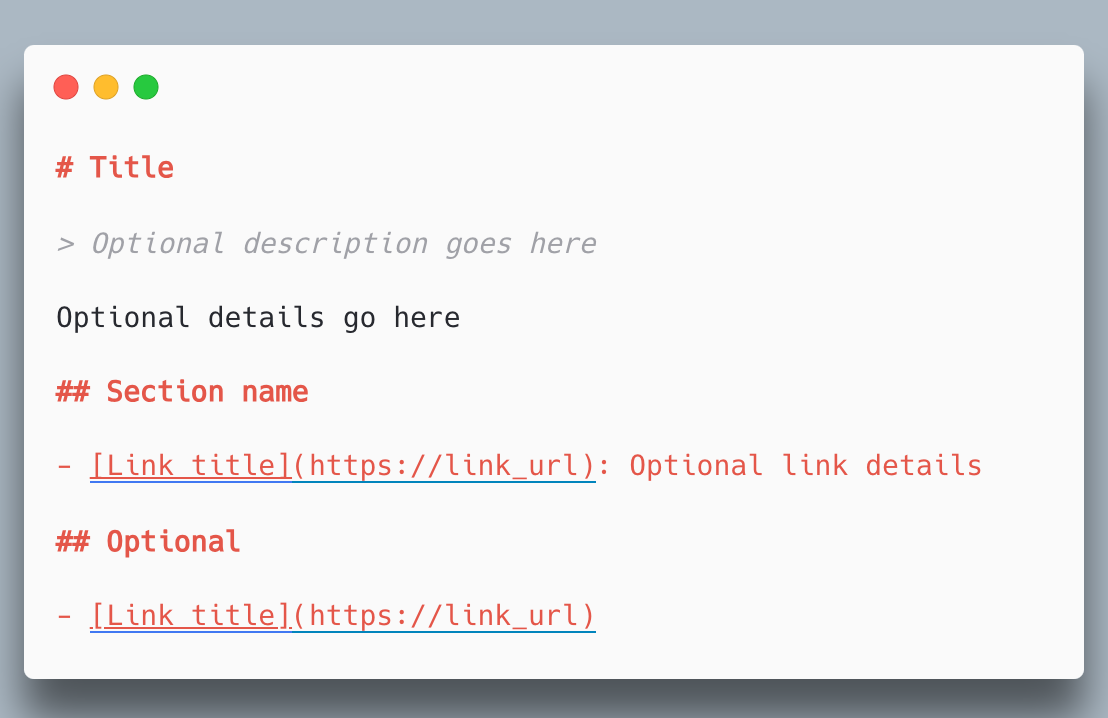
layouts/_default/index.llms.txt(軽量版):
# {{ .Site.Title }}
> {{ .Site.Params.description }}
author: zatoima
url: {{ .Site.BaseURL }}
## Blog Posts
{{- $pages := where .Site.RegularPages "Section" "blog" }}
{{ range $pages }}
- [{{ .Title }}]({{ .Permalink }}) ({{ .Date.Format "2006-01-02" }}){{ with .Params.tags }} [{{ delimit . ", " }}]{{ end }}
{{- end }}
layouts/_default/index.llms-full.txt(完全版):
{{- $pages := where .Site.RegularPages "Section" "blog" }}
{{ range $pages }}
---
### {{ .Title }}
date: {{ .Date.Format "2006-01-02" }}
url: {{ .Permalink }}
{{ .Plain }}
{{ end }}
3. HTMLヘッダーへのリンク追加
layouts/_default/baseof.htmlの<head>内に以下を追加する。
<link rel="alternate" type="text/plain" href="/llms.txt" title="LLMs.txt" />
<link rel="alternate" type="text/plain" href="/llms-full.txt" title="LLMs-full.txt" />
ナビゲーションにもリンクを追加した。
<a href="/llms.txt" title="LLMs.txt - AI/LLM向けサイト情報">llms.txt</a>
生成結果
| ファイル | 行数 | 内容 |
|---|---|---|
llms.txt |
414行 | 記事タイトル・URL・タグの一覧 |
llms-full.txt |
7,448行 | 全記事の本文を含む完全版 |
コンテキストウィンドウへの影響
MCP Serverはllms-full.txt(約1.8MB / 推定50万トークン)を起動時にHTTPで取得しメモリ上に保持する。しかし、この全データがClaude Codeのコンテキストウィンドウに流れるわけではない。
各ツールがClaude Codeに返すデータ量は以下の通り。
| ツール | 返すデータ | コンテキスト消費 |
|---|---|---|
search_posts |
タイトル一覧のみ | 小 |
list_posts |
タイトル一覧のみ | 小 |
list_tags |
タグと件数の集計 | 小 |
blog_stats |
統計サマリ | 小 |
read_post |
1記事の全文 | 記事による(大) |
read_post以外のツールは検索・集計結果のサマリのみを返すため、コンテキストウィンドウへの影響は小さい。1.8MBの全記事データはMCP Serverプロセスのメモリに留まり、Claude Codeには流れない。read_postだけは記事全文を返すため、長い記事の場合はコンテキストを圧迫する可能性がある。
まとめ
Hugo製の静的ブログに対して、2つの異なるアプローチでAI/LLMとの連携を実装した。
| 方式 | 用途 | 動作環境 | クローン |
|---|---|---|---|
| MCP Server | Claude Codeからの記事操作 | ローカル(Node.js) | 不要(HTTPフェッチ) |
| llms.txt | Web上でのLLM向けコンテンツ公開 | GitHub Pages(静的ファイル) | 不要 |
MCP Serverはllms-full.txtをHTTPで取得する方式にしたことで、リポジトリのクローンが不要になった。llms.txtがMCP Serverのデータソースを兼ねる構成になっており、Hugoビルド時に記事データが自動更新される。静的サイトでも工夫次第でAIフレンドリーな対応が可能である。