Spark Overview
Prerequisite concepts such as Executors and Partitions for Spark components:
Spark Memory Management Overview
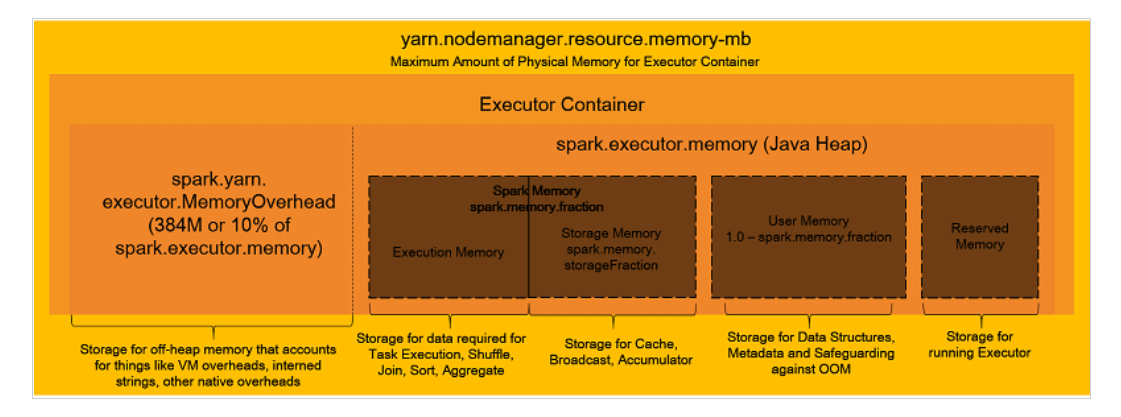
Memory Management Parameters
Calculations for each parameter based on instance type and node count when spark.dynamicAllocation.enabled is set to False, as described in the blog above. The calculation formulas are embedded in this Excel file
. By changing the yellow cells to match each instance type and actual environment, calculations should be done automatically.
This should only be used as initial sizing and should be tuned appropriately. In particular, the number of partitions should be determined by actually running the job.
| Instance type | r5.12xlarge | m5.8xlarge |
|---|---|---|
| vCPU | 48 | 32 |
| Memory | 384 | 128 |
| Node count | 5 | 5 |
| spark.executor.cores: Number of virtual cores per executor | 5 | 5 |
| spark.executor.memory: Memory size used by Executor | 9g | 6g |
| spark.yarn.executor.memoryOverhead: Overhead memory size for Executor | 1g | 1g |
| spark.driver.memory: Memory size for Driver | 9g | 6g |
| spark.driver.cores: Number of virtual cores for Driver | 5 | 5 |
| spark.executor.instances: Number of Executors per instance | 44 | 29 |
| spark.default.parallelism: Default value for number of Partitions | 440 | 290 |
Other Parameters
For other parameters, refer to the parameters listed in the blog and the Spark manual, and configure what is needed.
[
{
"Classification": "yarn-site",
"Properties": {
"yarn.nodemanager.vmem-check-enabled": "false",
"yarn.nodemanager.pmem-check-enabled": "false"
}
},
{
"Classification": "spark",
"Properties": {
"maximizeResourceAllocation": "false"
}
},
{
"Classification": "spark-defaults",
"Properties": {
"spark.driver.memory": "39G",
"spark.driver.cores": "5",
"spark.executor.memory": "39G",
"spark.executor.cores": "5",
"spark.executor.instances": "14",
"spark.executor.memoryOverhead": "5G",
"spark.driver.memoryOverhead": "5G",
"spark.default.parallelism": "140",
"spark.sql.shuffle.partitions": "140",
"spark.network.timeout": "800s",
"spark.executor.heartbeatInterval": "60s",
"spark.dynamicAllocation.enabled": "false",
"spark.memory.fraction": "0.80",
"spark.memory.storageFraction": "0.30",
"spark.executor.extraJavaOptions": "-XX:+UseG1GC -XX:+UnlockDiagnosticVMOptions -XX:+G1SummarizeConcMark -XX:InitiatingHeapOccupancyPercent=35 -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:OnOutOfMemoryError='kill -9 %p'",
"spark.driver.extraJavaOptions": "-XX:+UseG1GC -XX:+UnlockDiagnosticVMOptions -XX:+G1SummarizeConcMark -XX:InitiatingHeapOccupancyPercent=35 -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:OnOutOfMemoryError='kill -9 %p'",
"spark.yarn.scheduler.reporterThread.maxFailures": "5",
"spark.storage.level": "MEMORY_AND_DISK_SER",
"spark.rdd.compress": "true",
"spark.shuffle.compress": "true",
"spark.shuffle.spill.compress": "true",
"spark.serializer": "org.apache.spark.serializer.KryoSerializer"
}
}
]
Reference Materials
Apache Hadoop 3.3.1 – Using Memory Control in YARN